Top Words Research Methodology
Sampling Method
The data is based on all new daily domain name registrations of traditional and new gTLDs such as .com, .net, .club, .shop, etc. The data was processed in R and Python with a variety of generally available and custom dictionaries.
Layout of Methodology
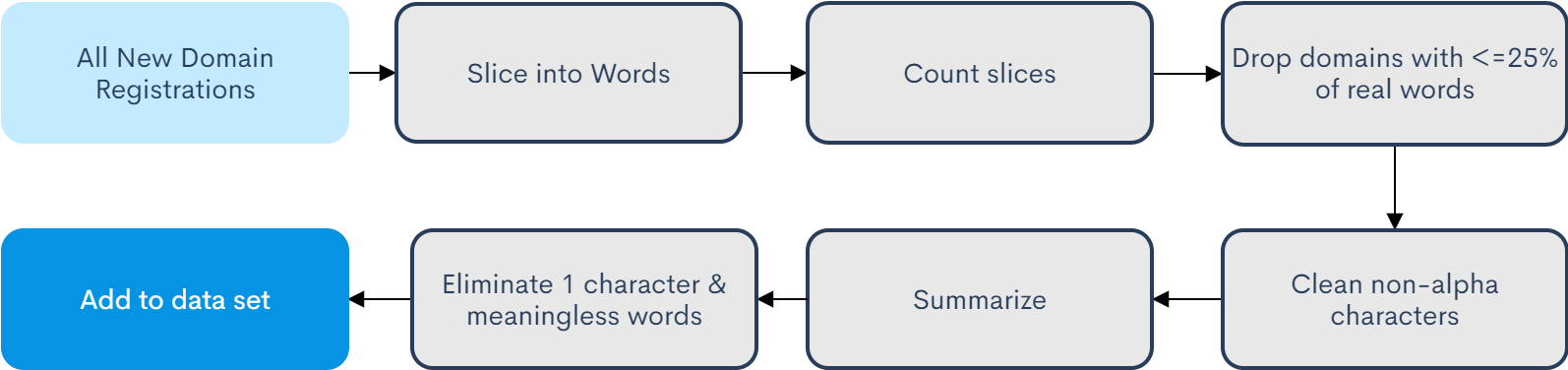
The volume of daily registration data and the resulting data added to the dataset will vary depending on seasonal fluctuations, quality of domain names and those that contain English terms. Meaningless words are pronouns, articles and prepositions that provide little value in identifying themes for instance, them, the, because, which, etc. Words that occur at least ten times are retained.
Why were domains with <=25% of real words removed? To retain the quality of the results for example, jembutnjkgfbjengbhtehbjgtrebhjgbjnrtebhjgrtjhrtyjnkhbrtetehgr.com results in a five slices: jem but njkgfbjengbhtehbjgtr ebhjgbjnrtebhjgrtjhr tyjnkhbrtetehgry and circumvents bloating.
Future Work/Iterations
As new slang and proper words are identified and added to the dictionary (for instance, Pacman), the volume of domain names removed could decline. This will be a gradual process that will improve over time.
Updates
Ranking of terms was last updated: June 2, 2021 (for the period of May 1-31, 2021).
Next update scheduled for: July 3, 2021